
Sep 2021 - Dec 2021, Northwestern Final Project
I. Introduction
Due to the increasing traffic demand and the difficulty of capacity expansion, the United States freeway system is facing many challenges. One of the most fundamental challenge is the congestion caused by traffic flow breakdown. The flow breakdown is defined as a transition from a free-flow state to a congested state of a traffic state at a certain location. It occurs when the arrival flow to the location exceeds its capacity. The limited mobility caused by such flow breakdown may result in more aggressive driving behavior which could further slowdown the recovery of the free traffic flow.
In order to address this challenge, the Connected Vehicle (CV) technology offers promising solutions through real-time information dissemination capability. Typical US highway capacity is around 2,200 vehicles per hour per lane and currently the vehicles could only occupy about 5% of the road surface at maximum capacity. In this report, the CV technology will be applied in order to improve one important case of the traffic flow breakdown: the on-ramp merging situation.
One basic method which is implemented throughout the country is ramp metering. Many ramp metering methods have been developed to improve both safety and throughput for the on-ramp merging process. One of the most fundamental algorithm for the ramp metering control is the ALINEA algorithm. The key idea behind ramp metering is to dynamically determine the appropriate cycle time for the traffic light for the on-ramp traffic. The application of ramp metering does usually improve the traffic flow on the main road, especially in increasing the mean speed and decreasing the average travel time. However, since the traffic control of the on-ramp vehicles provided by ramp metering is so arbitrary, it is not guaranteed to be consistently effective throughout the day, especially when a vehicle from the on-ramp is released by the ramp meter and unfortunately hit into a large arbitrarily formed platoon of main road vehicles. Such a situation could not only negatively affect the traffic flow, but also the safety of all the vehicles involved.
However, by involving connected vehicles in the ramp merging situation, those negative effects mentioned above can be largely prevented. First of all, When the vehicles are all connected, centralized control strategies can be deployed to provide a macroscopic control of the whole traffic, including the ramp merging. Platoons can be formed according to the specific arrangement from the centralized control. Second, the compliance of the connected vehicles is likely to be much higher than the regular vehicles as they could receive guidance or instructions on things like speed, acceleration, deceleration, changing lane, etc. And given that following such guidance or instructions could largely save their own time and increase their own safety, extra incentives of being compliant is created and noticed.
In order to achieve the improvement mentioned above, I proposed a safety-assured deep reinforcement learning model for cooperative highway ramp merging. It is based on the FLOW project proposed by UC Berkeley.
II. Background
FLOW
Flow is created by and actively developed by members of the Mobile Sensing Lab at UC Berkeley (PI, Professor Bayen).
Flow is a traffic control benchmarking framework. It provides a suite of traffic control scenarios (benchmarks), tools for designing custom traffic scenarios, and integration with deep reinforcement learning and traffic microsimulation libraries.
Ray
Ray is an open source project that makes it simple to scale any compute-intensive Python workload — from deep learning to production model serving. With a rich set of libraries and integrations built on a flexible distributed execution framework, Ray makes distributed computing easy and accessible to every engineer.
SUMO (Simulation of Urban MObility)
SUMO is an open source, highly portable, microscopic and continuous multi-modal traffic simulation package designed to handle large networks.
III. Purpose and scope
Limitation of the FLOW
The main idea of this project in general is to improve one of the limitations involved in the merging scenario benchmark provided by FLOW. The details of the merging scenario research study can be found in the paper Dissipating stop-and-go waves in closed and open networks via deep reinforcement learning. This article demonstrates the ability for modelfree reinforcement learning techniques to generate traffic control strategies for connected and automated vehicles (CAVs) in a highway ramp merging scenario. This method is demonstrated to achieve near complete wave dissipation in a straight open road network with a certain CAV penetration. A snippet of its performance is demonstrated below:

As demonstrated in the GIF, the red vehicles are representing the CAVs involved in the scenario, the blue vehicles are the ones that are observed by the CAVs, and the white vehicles are the merging vehicles. Since the inflow rate of the merging vehicles is set to be a fixed number, the merging vehicles are appearing at a fixed frequency. While this could be a somewhat realistic simulation of the merging situation, the deep reinforcement learning agent seemed to be learning the rate of appearance of the merging vehicles. Which means the agents are predicting when the merging vehicles are going to arrive at the merging point, without actually observing it. As a result, it can be observed that the red CAVs are forming gaps right at the point where the merging vehicle appears. This observational assumption can be further demonstrated below:
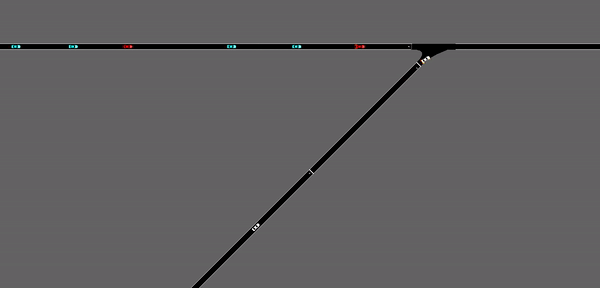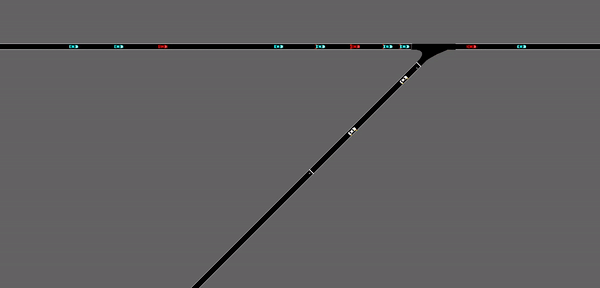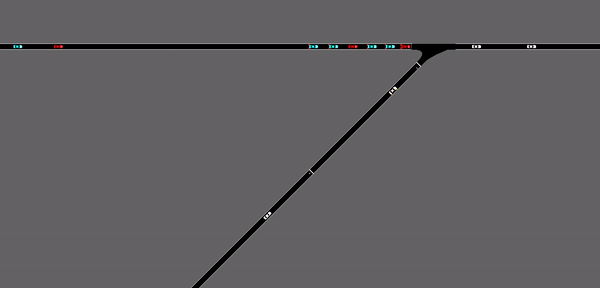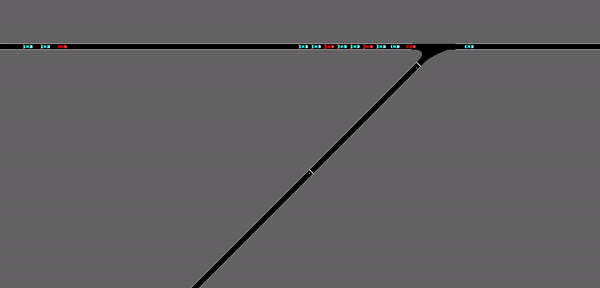
This is a demonstration of the performance of the same deep reinforcement learning agent after changing the fixed merging inflow rate into a probability merging inflow rate. That is to say, the merging vehicles are appearing at a certain probability, which simulates the random appearance of vehicles on the highway ramp. In this case, the same stop-and-go waves are appearing again and is not alleviated by a lot by the RL agent.
Proposed Solution
In order to alleviate the stop-and-go waves in a highway ramp merging scenario with random merging inflow, I implemented a ramp meter on the merging road which is also a part of the single reinforcement learning agent. Ramp meters are traffic signals installed on freeway on-ramps to control the frequency at which vehicles enter the flow of traffic on the freeway. Ramp metering reduces overall freeway congestion by managing the amount of traffic entering the freeway and by breaking up platoons that make it difficult to merge onto the freeway.

As can be observed from the benchmark performance of the FLOW demonstrated above, the CAVs would accelerate or decelerate at some point to form platoons of vehicles together with the vehicles that are not CAVs. In the benchmark case, the gaps are formed more or less arbitrarily and the merging vehicles would be merging into the gaps all by chance. By adding the intelligent ramp meter which has access to all the observations made by the CAVs on the main road, the whole agent is able to determine if there is a safe and stable gap formed on the main road for the merging vehicles to merge in. And if so, the agent would send a command to the ramp meter to release the merging vehicles so that they can merge in right at the moment where the gap is available at the merging point.
IV. Reinforcement Learning Design
State
For the state space, the agent is observing the position and speed of all the CAVs and all the vehicles that are observed by the CAVs on the main road. Such information can theoretically be transferred by the agent into information about the gaps formed by the platoons on the main road, including the position and speed of the gaps.
Action
In terms of the action space, the agent is controlling both the CAVs and the ramp meter. For the CAVs, the action space is sending out commands of the desired acceleration or deceleration for each individual CAV. For the ramp meter, for the simplicity of implementation, the action space is also making decisions in terms of acceleration by treating the ramp meter as an individual CAV that is always on the road. After acceleration decision has been made for the ramp meter, the command is then transferred from continuous to discriminant command by simply checking if the acceleration is positive or negative. I.e. if the agent sends out positive acceleration command to the ramp meter, it is going to be interpreted by the ramp meter as a command to turn green, and Vice Versa.
Reward
The reward function of the reinforcement learning agent comes in as three parts:
1. Desired Speed
This function measures the deviation of a system of vehicles from a user-specified desired velocity peaking when all vehicles in the scenario are set to this desired velocity. Moreover, in order to ensure that the reward function naturally punishing the early termination of rollouts due to collisions or other failures, the function is formulated as a mapping. This is done by subtracting the deviation of the system from the desired velocity from the peak allowable deviation from the desired velocity. Additionally, since the velocity of vehicles are unbounded above, the reward is bounded below by zero, to ensure nonnegativity.
2. Time Headways
Time headway is defined as the time difference between any two successive vehicles when they cross a given point. Practically, it involves the measurement of time between the passage of one rear bumper and the next past a given point. The reward function would penalize the small time headways that are appearing on the road to make sure that all the vehicles are keeping a safe distance between each other.
3. Emergent Brakes
The emergent brakes are one of the main reasons behind the stop-and-go behavior at the merging point, and such behavior can be captured by keep track of the deceleration of all the vehicles on the road. Whenever there is a vehicle decelerating more than a certain threshold, the reward function would take that into account and penalize the total reward calculated.
V. Performance
After implementing the RL design mentioned above, an agent is trained and its performance is shown below:
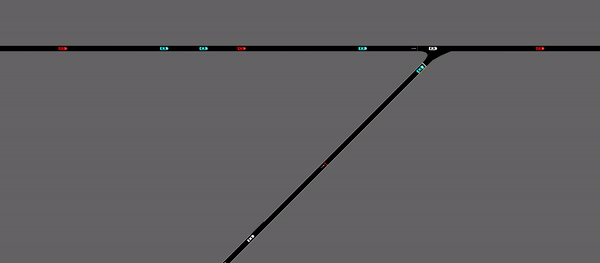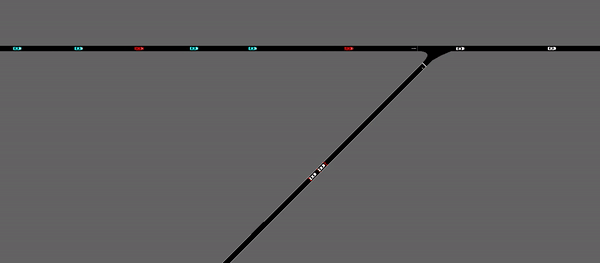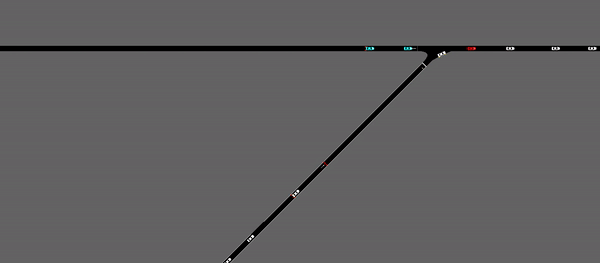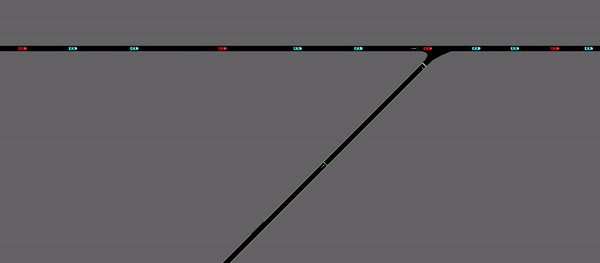
As demonstrated above, the merging vehicles are stopped at the ramp meter until the whole agent determines that there is an acceptable merging gap formed within the platoons on the main road. In general, it is achieving similar performance with the agent without ramp meter, in terms of mean velocity and outflow rate. However, by implementing the ramp meter, the standard deviation of the speed of the vehicles on the road is largely decreased, which indicates a more consistent and stable driving behavior.
VI. Future Work
The next step of this project would be focused on comparing the different methods with metrics for evaluation. With such more formal comparison and performance evaluation, an academic research paper should be written and hopefully published at some research journal.